Redis 笔记(五):分布式缓存-分片集群
1 概述
主从和哨兵可以解决 Redis 高可用、高并发读的问题。但是仍有两个问题没有解决:
- 海量数据存储
- 高并发写
使用分片集群可以解决上述问题,分片集群的特征是:
- 集群中有多个 master,每个 master 保存不同数据。
- 每个 master 都可以有多个 slave 节点
- master 之间通过 ping 监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
2 hash slot (散列插槽)
Redis 会把每一个 master 节点映射到 0~16383 共 16384 个插槽上
数据 key 不是与节点绑定,而是与插槽绑定。Redis 会根据 key 的有效部分计算插槽值,分两种情况:
- key 中包含 “{}”,且 “{}” 中至少包含 1 个字符,”{}” 中的部分是有效部分
- key 中不包含 “{}”,整个 key 都是有效部分
例如:key 是 num,那么就根据 num 计算,如果是 {hello}num,则根据 hello 计算。计算方式是利用 CRC16 算法得到一个 hash 值,然后对 16384 取余,得到的结果就是 slot 值。
Redis 是如何判断某个 key 应该在哪个实例上的?
- 在创建集群时,将 16384 个插槽分配到各个实例(节点)上
- 当存储/获取一个 key 时,根据 key 的有效部分计算哈希值
-> 对 16384 取余得到插槽值
-> 寻找插槽所在实例(节点)
如何将同一类数据固定保存在同一个 Redis 实例(为了避免请求重定向带来的性能损耗)?
这一类数据使用相同的有效部分,例如 key 都以 {typeId} 为前缀
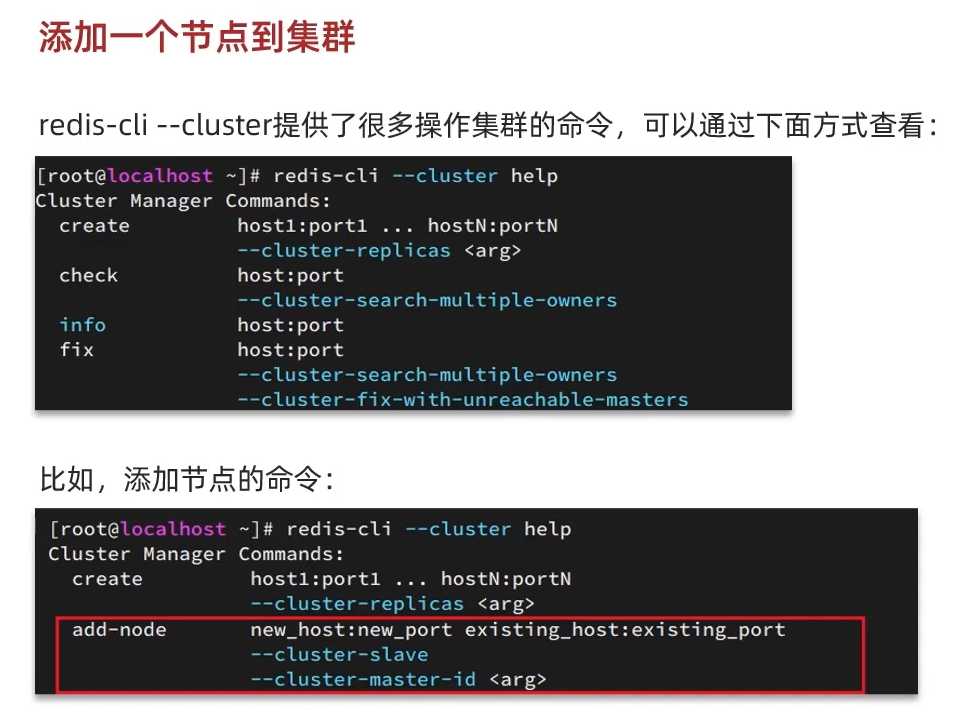
3 Cluster Scaling (集群伸缩)
4 Failover (故障转移)
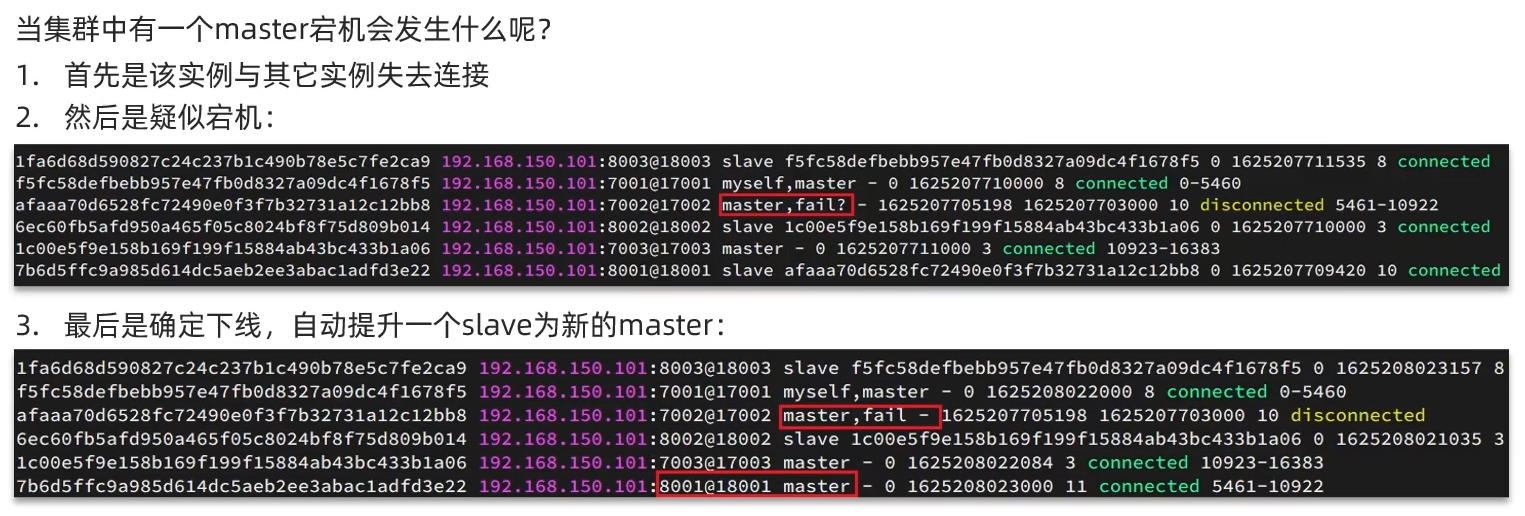
Automatic Failover(自动故障转移)
为了避免服务宕机而引起的数据损失
Manual Failover(手动故障转移)
有目的性的服务升级(数据迁移)
利用 cluster failover 命令可以手动让集群中的某个 master宕机,切换到执行 cluster failover 命令的这个 slave 节点,实现无感知的数据迁移。流程如下:
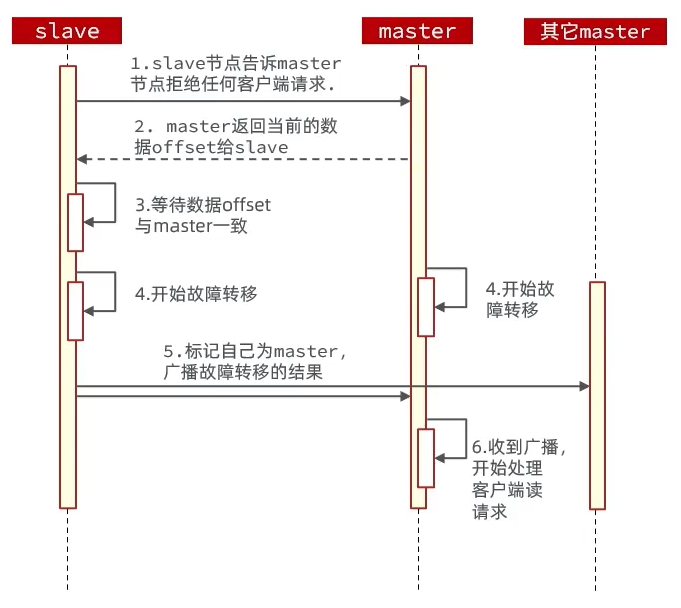
手动的 failover 支持三种模式:
- 缺省:默认的流程,如上图
- force:省略了对 offset 的一致性校验(不交接工作,比较暴力)
- takeover:直接执行第 5 步,忽略数据一致性、忽略 master 状态和其他 master 的意见(更加暴力)
5 RedisTemplate 访问分片集群

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 ...!